8⽉27⽇,智谱AI的BigModel开放平台宣布:大模型GLM-4-Flash调用全部免费!
然后我就赶紧去试试了(薅羊毛)!新用户可以免费⽀持2个并发,128上下文,个⼈使⽤是够够的了。

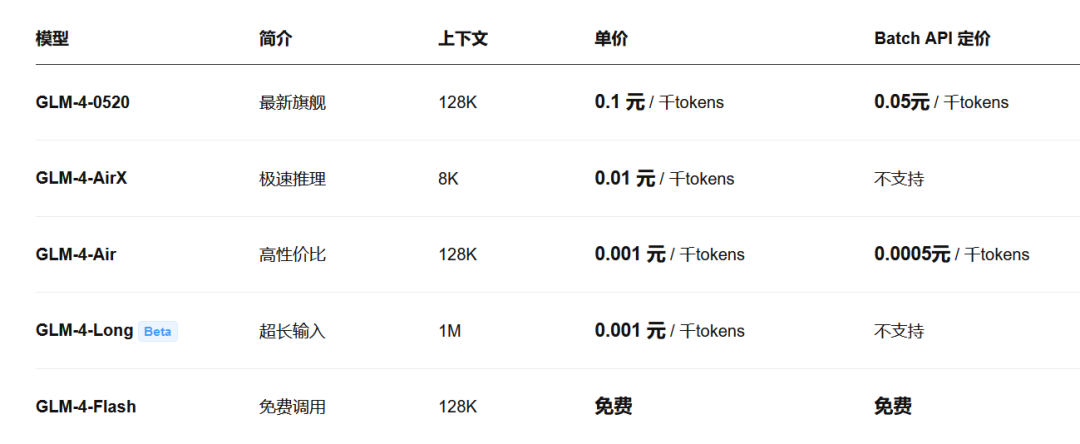
GLM-4-Flash模型介绍
GLM-4-Flash,堪称“最能打的小模型”,是智谱AI所推出的GLM-4系列预训练模型的开源版本。在叠加调用免费的优势,简直是无敌了!
GLM-4-Flash经全面测评,在语义理解、数学逻辑、逻辑推理、代码执行以及广泛知识覆盖等方面,其表现显著超越了Llama-3-8B模型。
GLM-4-Flash模型还具备多种核心功能,包括但不限于流畅的多轮对话能力、内置的网页浏览功能、直接的代码执行支持、灵活的自定义工具调用接口,以及卓越的长文本推理性能(支持处理最大128K的上下文内容),这些功能造就了GLM-4-flash强大的智能化应用能力。
模型优势
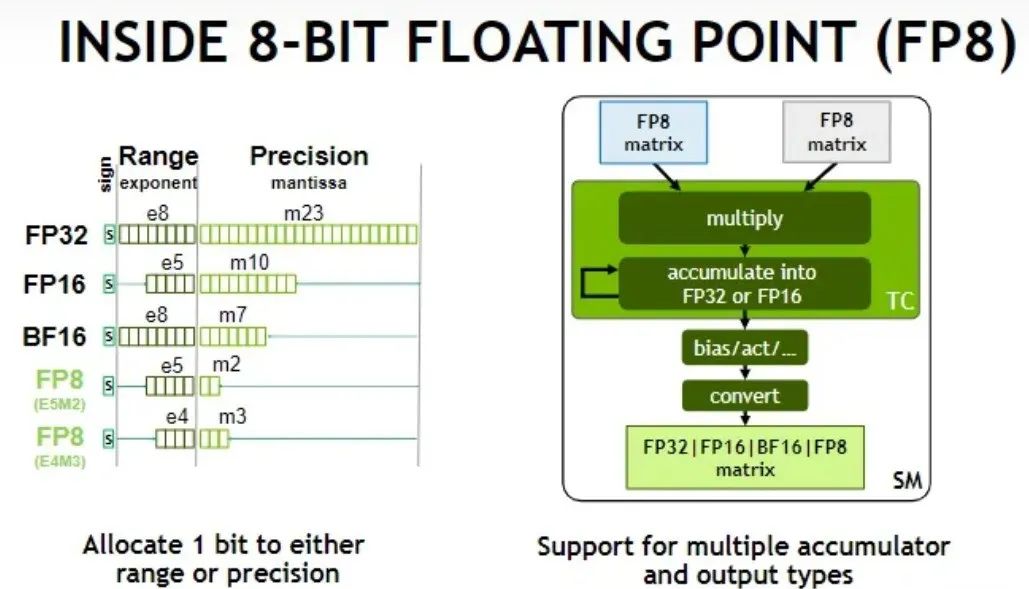
GLM-4-Flash所展示的高性能,归功在数据预处理的精细度、预训练技术的创新性以及模型能力的卓越性上,共同构筑了这款高性能多语言处理模型。数据预训练:在GLM-4-Flash的开发过程中,团队创造性地引入了大语言模型作为数据筛选的核心驱动力。这一策略不仅大幅提升了数据筛选的精准度,还确保了所收集数据的多样性与高质量。通过这一先进流程,GLM-4-Flash成功汇聚了超过10TB的优质多语言数据资源,这些数据覆盖了广泛的领域与语境,为模型的学习与泛化能力奠定了坚实的基础。预训练技术:为了进一步提高训练效率并优化计算资源的使用,GLM-4-Flash采用了前沿的FP8(半精度浮点数)技术进行高效的预训练。FP8技术通过减少数据表示所需的比特数,显著降低了计算过程中的内存占用和功耗,从而在不影响模型精度的前提下,实现了训练速度的飞跃式提升。这一创新不仅缩短了模型的开发周期,还降低了整体运营成本,使得GLM-4-Flash在应对大规模数据集时展现出前所未有的高效性。
模型能力:GLM-4-Flash模型的核心竞争力在于其强大的推理性能与多语言能力。该模型支持长达128K的上下文推理,这一能力远超传统模型,使得GLM-4-Flash能够更准确地理解复杂的长文本语境,从而生成更加连贯、贴切的响应。同时,作为一款多语言处理模型,GLM-4-Flash能够无缝处理多种语言的输入,无论是常见的英文、中文,还是其他小众语言,都能保持高水平的处理质量和效率。这种跨语言的通用性极大地拓宽了模型的应用场景,满足了全球化背景下多样化的语言处理需求。
模型调用示例
GLM-4-Flash已在大型模型即服务(MaaS)平台bigmodel.cn上发布,用户完成注册流程后,即可亲身体验其卓越的视频创作能力。
首先,请打开智谱官网 https://bigmodel.cn/,随后直接使用您的手机号进行注册。完成注册并成功登录后,在后台页面的右上角,有一个名为“API秘钥”的选项。轻轻一点,便会展现出API秘钥
有了秘钥后,接口请求方式有两种,一种是使用 HTTP 接口,另外一种是使用官方提供的 SDK。如果你在项目中使用,更推荐安装 SDK。
为便于开发者高效利用GLM-4-Flash的强大功能,以下将通过Python SDK的使用指南,详细阐述如何调用该服务。详细文档请参考:https://open.bigmodel.cn/dev/
1、SDK安装与初始化
首先,请确保您已安装或更新至最新版本的智谱AI SDK。若尚未安装,可通过以下命令进行安装:
pip install zhipuai若已安装但非最新版本,请使用以下命令进行升级:
pip install --upgrade zhipuai安装完成后,您可以通过以下代码引入智谱AI客户端,并初始化API密钥:
from zhipuai import ZhipuAI # 初始化客户端,请替换'你的API_KEY'为您的实际API密钥client = ZhipuAI('你的API_KEY')
2、调用代码
如下为完整的调用示例代码:
from zhipuai import ZhipuAIclient = ZhipuAI(api_key="") # 请填写您自己的APIKeyresponse = client.chat.completions.create(model="GLM-4-Flash", # 填写需要调用的模型编码messages=[{"role": "system", "content": "你是一个乐于解答各种问题的助手,你的任务是为用户提供专业、准确、有见地的建议。"},{"role": "user", "content": "我对太阳系的行星非常感兴趣,特别是土星。请提供关于土星的基本信息,包括其大小、组成、环系统和任何独特的天文现象。"},],stream=True,)for chunk in response:print(chunk.choices[0].delta)
应用示例
作为人工智能领域的一个开发者,平时无非是写写代码,看看前沿的论文。而通过GLM-4-Flash,这方面的工作明显更加得心应手了。写代码的话我们扔个代码需求给他,就可以产出代码,我自己在稍微运行调试一下就能用了。
写一段iris聚类的python示例代码from sklearn import datasetsfrom sklearn.cluster import KMeansimport numpy as np# 加载Iris数据集iris = datasets.load_iris()X = iris.data# 应用KMeans聚类算法,这里我们假设有3个类别(对应Iris数据集的3个品种)kmeans = KMeans(n_clusters=3, random_state=0)kmeans.fit(X)# 输出聚类结果print("聚类标签:")print(kmeans.labels_)# 输出每个簇的中心点(均值)print("每个簇的中心点:")print(kmeans.cluster_centers_)# 输出每个样本的类别概率(即属于每个类别的概率)print("每个样本的类别概率:")print(kmeans.predict_proba(X))
我们可以根据结果,加一些代码需求,比如下面这样:
将分类结果画出散点图,标注下模型分类的效果import matplotlib.pyplot as pltfrom sklearn import datasetsfrom sklearn.cluster import KMeansimport numpy as np# 加载Iris数据集iris = datasets.load_iris()X = iris.datay = iris.target# 应用KMeans聚类算法,这里我们假设有3个类别(对应Iris数据集的3个品种)kmeans = KMeans(n_clusters=3, random_state=0)kmeans.fit(X)# 获取聚类结果labels = kmeans.labels_# 为每个样本绘制散点图plt.figure(figsize=(14, 7))# 绘制真实标签的散点图for i in range(3):plt.scatter(X[y == i, 0], X[y == i, 1], label=f'Class {i}')# 绘制KMeans聚类结果for i in range(3):plt.scatter(X[labels == i, 0], X[labels == i, 1], c='red', marker='x', label=f'Cluster {i}')plt.title('Iris Clustering with KMeans')plt.xlabel('Sepal length (cm)')plt.ylabel('Sepal width (cm)')plt.legend()plt.show()#运行这段代码后,你将得到一个包含三个不同颜色散点的图,以及用红色十字表示的聚类结果。图中的红色十字将位于真实类别中心附近,表示KMeans聚类算法的效果。
另外一个需求是是论文阅读和翻译,我们很经常要追踪AI最新的英文论文,普通的翻译软件经常翻译会比较生硬,比如很多术语软件直接就会直译, Transformer直接翻译成变形金刚,而通过GLM-4-Flash就可以很生动准确地翻译好。
你是一个人工智能专家,请翻译下这段论文:The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
如下为翻译《Attention is all you need》摘要的结果,术语翻译很准确,可以感受到翻译质量还是很不错的:
主要的序列转换模型是基于编码器-解码器配置的复杂循环神经网络或卷积神经网络。表现最好的模型还通过注意力机制连接编码器和解码器。我们提出了一种新的简单网络架构,称为Transformer,它完全基于注意力机制,摒弃了循环和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上更胜一筹,同时更易于并行化,并且训练时间显著减少。在我们的模型中,WMT 2014英语到德语翻译任务上实现了28.4 BLEU的分数,超过了现有的最佳结果,包括超过2 BLEU的集成模型。在WMT 2014英语到法语翻译任务上,我们的模型在8个GPU上训练了3.5天之后,达到了41.8的新单模型BLEU最佳分数,这是文献中最佳模型训练成本的一小部分。我们通过将Transformer成功应用于英语成分句法分析和大量及有限训练数据,展示了该模型在其它任务上的泛化能力。
开发文档链接
GLM-4-Flash已经在BigModel开放平台免费开放了,并同时开启了限时免费微调活动。具体可以参照官文文档~
相关文章
