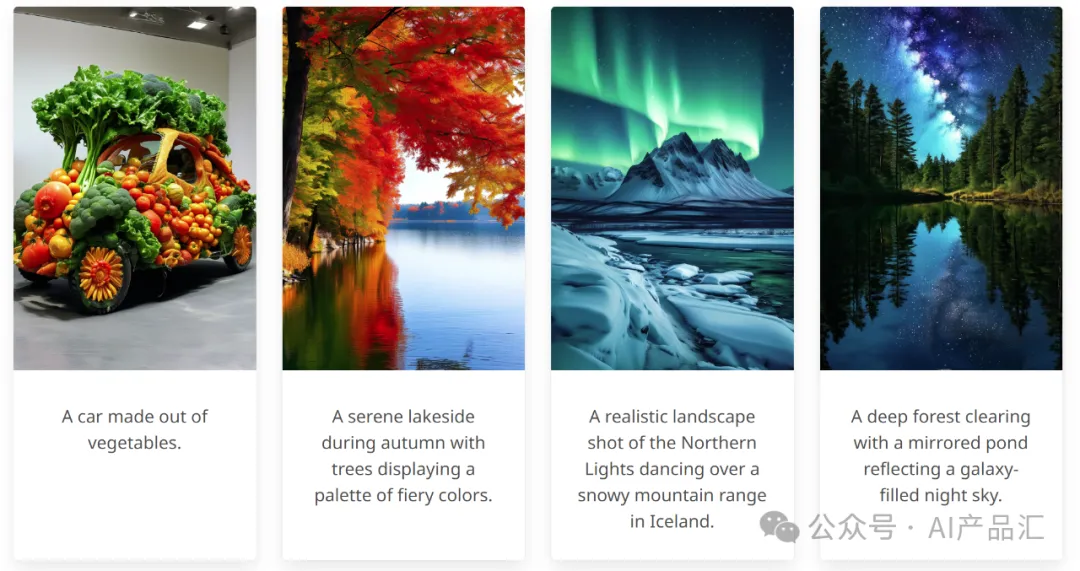
“ 文生图子领域一直都是一个比较热门的话题,虽然当前已经有很多文生图算法,但是这些主流的算法与工具,主要都是被国外的一些公司所垄断,例如:Stable Diffusion、Midjourney、ControlNet等。尽管国内也有很多文生图算法,但是很多算法的效果真的是一言难尽!本文小编给大家介绍一个支持生成高清4K大图的纯国产文生图算法-PixArt-Σ。PixArt-Σ是一种能够直接生成4K高清分辨率图像的扩散变换器模型(DiT),由华为、大连大学、香港大学一起合作推出。PixArt-Σ比其前身PixArt-α有了显著的进步,能够提供更加高保真度的高清图像,并改进了与文本提示的对齐思路。 ”
01-PixArt算法发展历程
2023年,Junsong Chen, Jincheng Yu,等人提出“PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthe sis”算法。本文介绍了PIXART-α,这是一种基于Transformer的T2I扩散模型,其图像生成质量与最先进的图像生成器(如Imagen、SDXL,甚至Midtravel)具有竞争力,达到了接近商业应用标准。此外,它支持高达1024px分辨率的高分辨率图像合成,训练成本低。为了实现这一目标,作者提出了三个核心设计:1)训练策略分解:设计了三个不同的训练步骤,分别优化像素依赖性、文本图像对齐和图像美学质量;2) 高效的T2I变换器:将交叉注意力模块引入到扩散变换器(DiT)中,以注入文本条件并简化计算密集型类条件分支;3) 高信息量数据:强调文本-图像对中概念密度的重要性,并利用大型视觉语言模型自动标记密集的伪字幕,以帮助文本-图像对齐学习。
2024年,Junsong Chen, Yue Wu等人提出“PIXART-δ: Fast and Controllable Image Generation with Latent Consistency Models”算法。本文介绍了PIXART-δ,这是一种文本到图像的合成框架,将潜在一致性模型(LCM)和ControlNet集成到高级PIXART-α模型中。PIXART-α因其通过非常有效的训练过程生成1024px分辨率的高质量图像的能力而受到认可。LCM在PIXART-δ中的集成显著加快了推理速度,仅需2-4步即可生成高质量图像。值得注意的是,PIXART-δ在生成1024×1024像素图像方面实现了0.5秒的突破,比PIXART–α提高了7倍。此外,PIXART-δ被设计为可在一天内在32GB V100 GPU上有效训练。

02-PixArt-Σ算法简介

得益于这些改进,PixArt-Σ实现了卓越的图像质量和遵守用户提示能力,其模型大小(0.6B参数)明显小于现有的文本到图像扩散模型,如SDXL(2.6B参数)和SD Cascade(5.1B参数)。此外,PixArt-Σ生成4K图像的能力支持高分辨率海报和壁纸的创建,可以很好的支持电影和游戏等行业高质量视觉内容的生产。
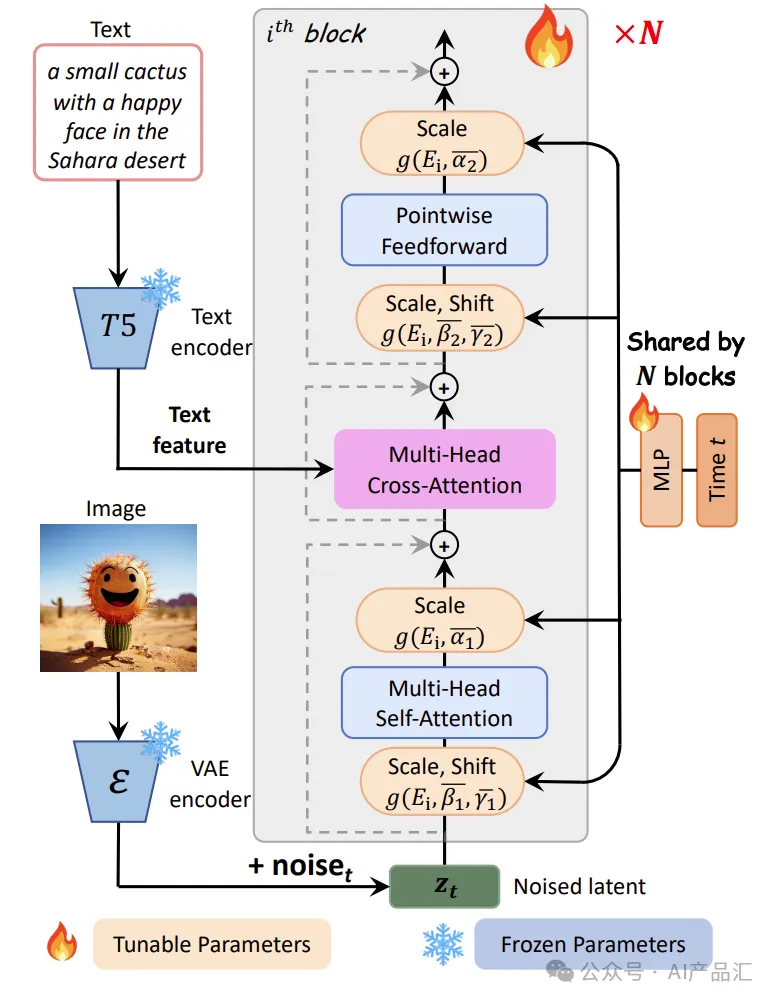
由于PixArt-Σ算法是在PixArt-α算法的基础上面演进而来。上图展示了PixArt-α算法的模型体系架构。在每个块中集成了一个交叉注意力模块,用来注入文本条件。为了优化效率,所有块在时间条件下共享相同的adaLN单个参数。详细的步骤如下所述:
- 首先,将输入的文本和图像分别输入到一个T5文本编码器和一个VAE编码器中获取特征表示;
- 然后,在VAE编码特征上面增加部分噪声,形成带有噪声的隐特征表示。
- 接着,将含有噪声的隐特征表示和文本特征一起输入到由N个Transformer块组成的特征解码器中;
- 最后,所有块在时间条件下共享相同的adaLN单个参数,获得最终的输出结果。
重新参数化–为了利用上述预训练的权重,所有E(i)的值都被初始化为产生与所选t的没有c的DiT相同的s(i)(根据经验使用t=500)。该设计用全局MLP和特定可训练嵌入层有效地替换了特定MLP层,同时保持了与预训练权重的兼容性。
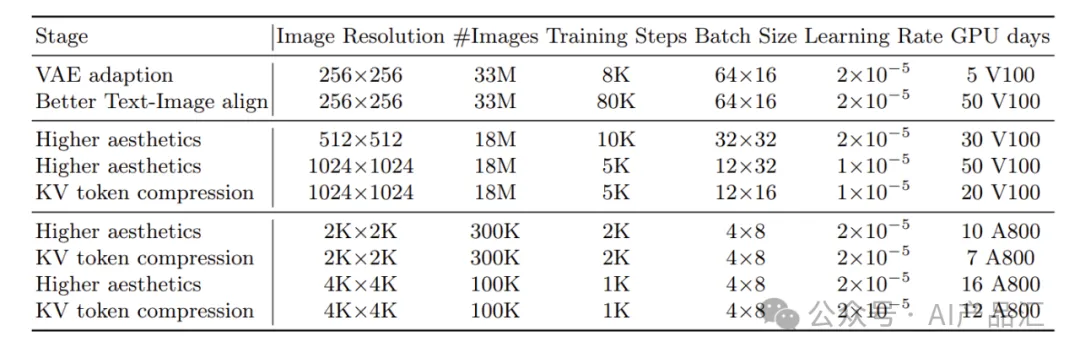
上表提供了PixArt-Σ算法在每个训练阶段的详细信息,包括图像分辨率、训练样本的总体积、训练步骤的数量、批量大小、学习率以及以GPU天为单位测量的计算时间。利用Internal-Σ数据集并集成了更先进的VAE,该方法只需5天的V100 GPU就可以快速适应新的VAE。随后,仅使用50天的V100 GPU来实现卓越的文本图像对齐。

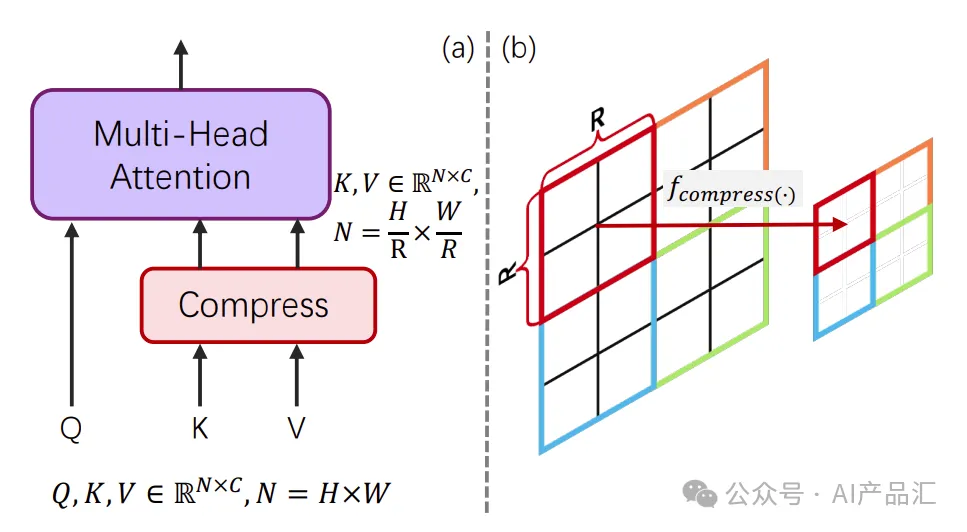
使模型适应KV压缩–当从LR预训练模型进行微调时直接使用KV压缩。如图(c)所示,通过“Conv Avg Init.”策略,PixArt-Σ从更好的初始状态开始,使收敛更容易、更快。值得注意的是,PixArt-Σ即使在100个训练步骤内也能获得令人满意的视觉效果。最后,通过KV压缩算子和压缩层设计,可以减少-34%的训练和推理时间。
05.01-主观效果评估
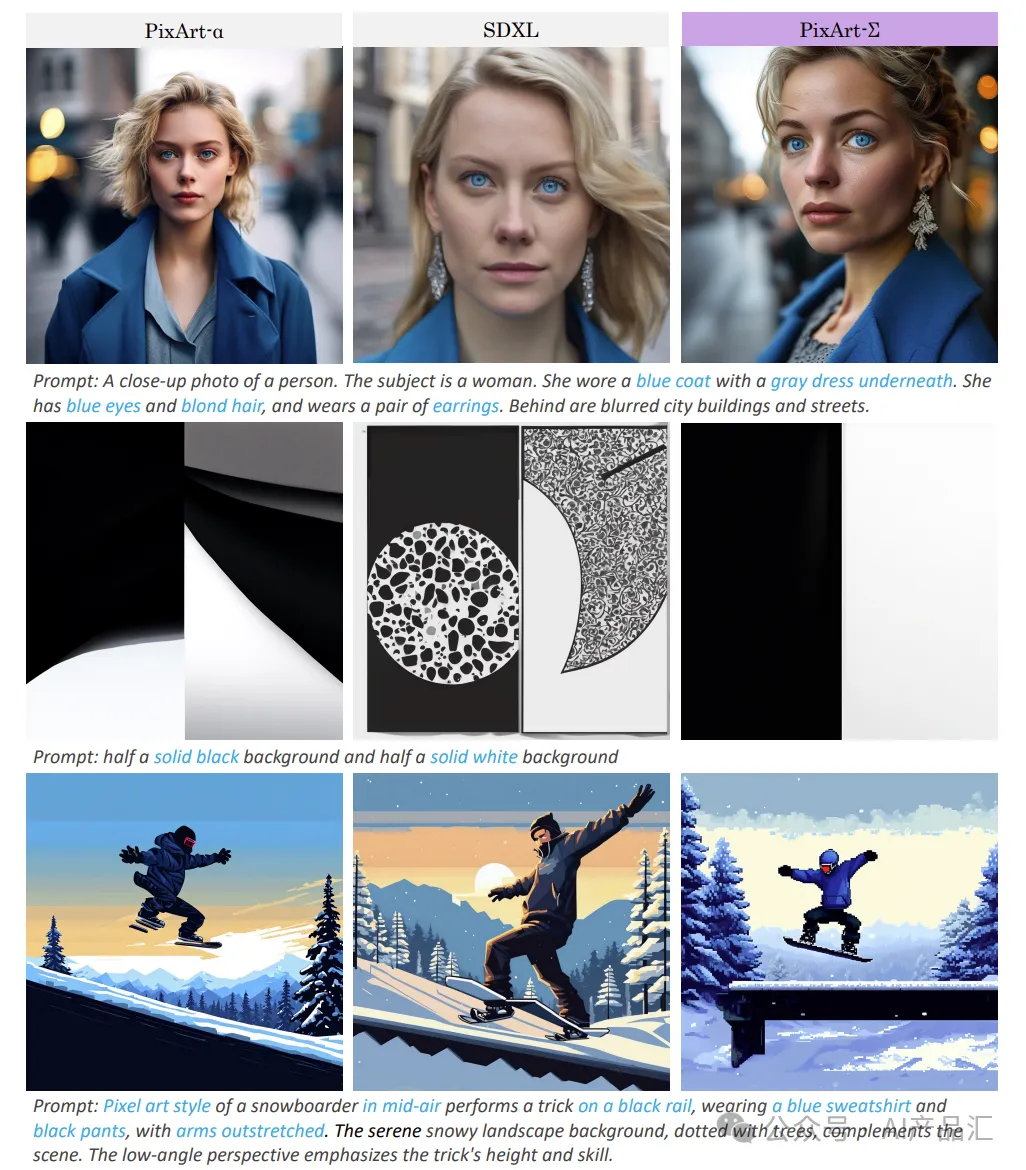
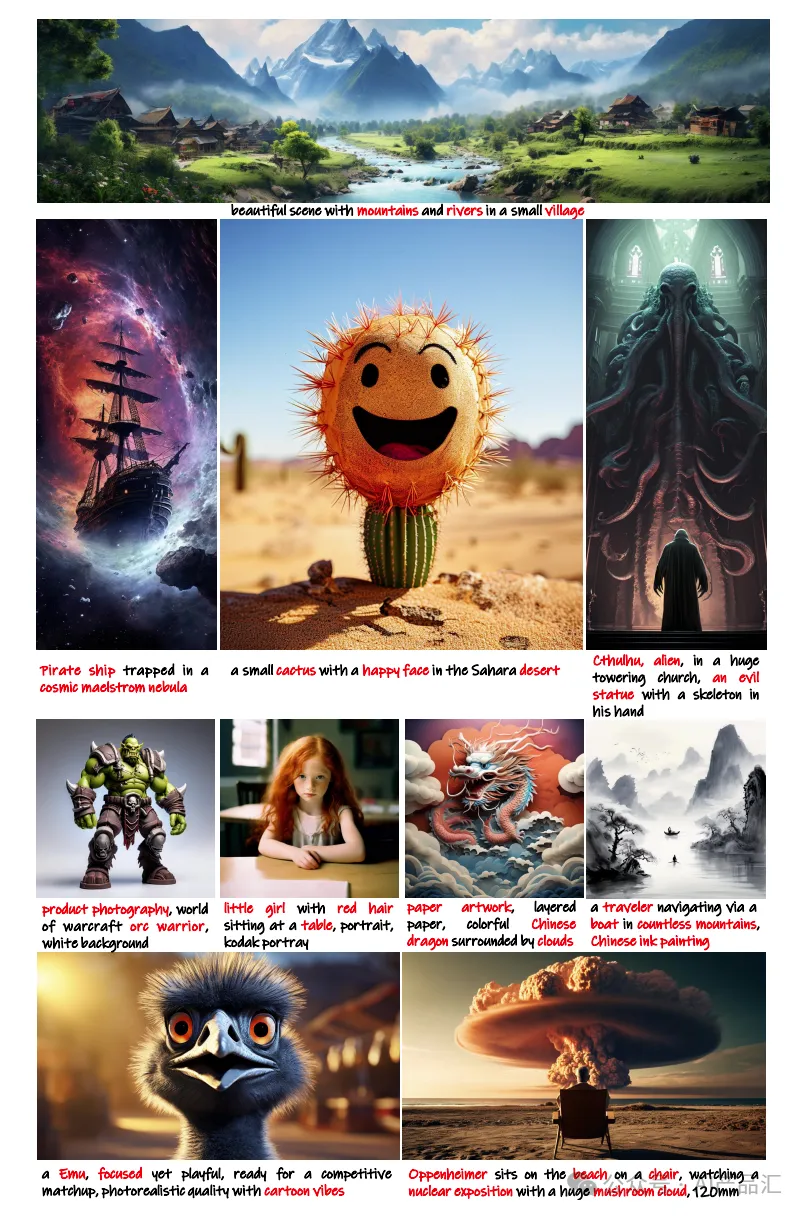
上图展示了PixArt-Σ与一些开源模型(如PixArt-α和SDXL)在相同的文本提示下的生成效果:与PixArt-α相比,PixArt-Σ显著提高了肖像的真实感和语义分析能力。与SDXL相比,该方法具有更好的遵循用户指令的能力。其中关键字高亮显示为蓝色。






上图展示了PixArt-Σ和其它四款T2I产品:Firefly 2、Imagen 2、Dalle 3和Midjourney V6在相同的文本提示下的生成效果。通过观察,我们可以发现:PixArt-Σ生成的图像与这些商业产品相比非常具有竞争力。
05.02-客观指标评估
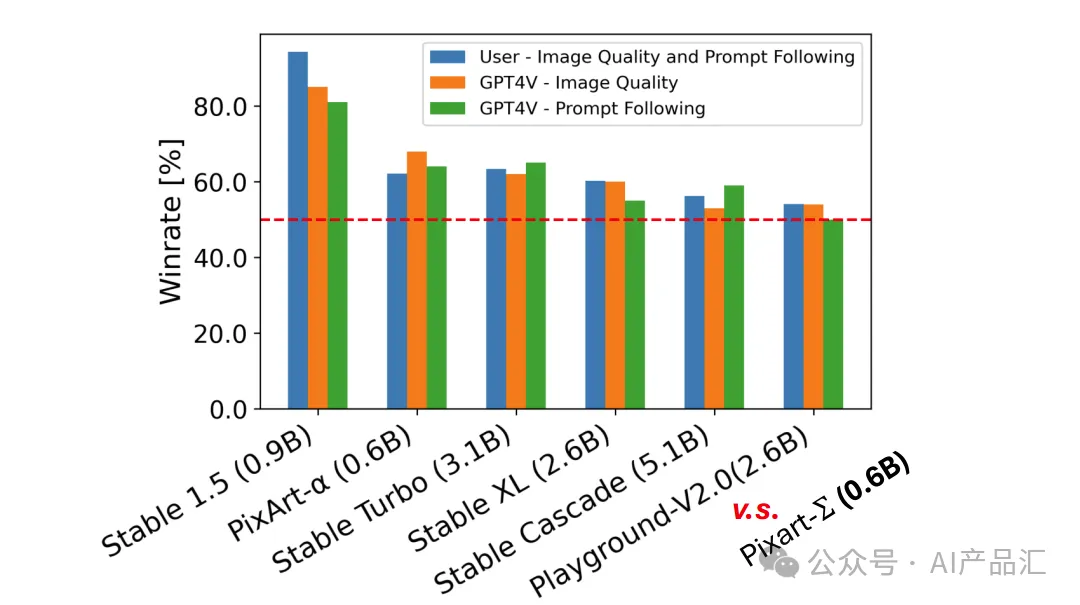
上表展示了针对当前开放T2I模型的人类(蓝色)/AI(橙色和绿色)偏好评估结果。图中分别展示了Stable 1.5、PixArt-α、Stable Turbo、Stable XL、Stable Cascade、Playground-V2.0和该算法的比较结果。
作者使用先进的多模式模型GPT-4 Vision作为评估者。对于每个试验,作者为GPT-4 Vision提供两张图像:一张来自PixArt-Σ,另一张来自竞争的T2I模型。通过制作了不同的提示,引导GPT-4 Vision根据图像质量以及图像和文本对齐进行投票。具体而言,PixArt-Σ的有效性超过了基线PixArt-α。与Stable Cascaded等当代先进模型相比,PixArt-Σ在图像质量和指令跟随能力方面表现出竞争力或卓越的性能。PixArt-Σ在图像质量和即时跟随方面都优于当前最先进的T2I模型。
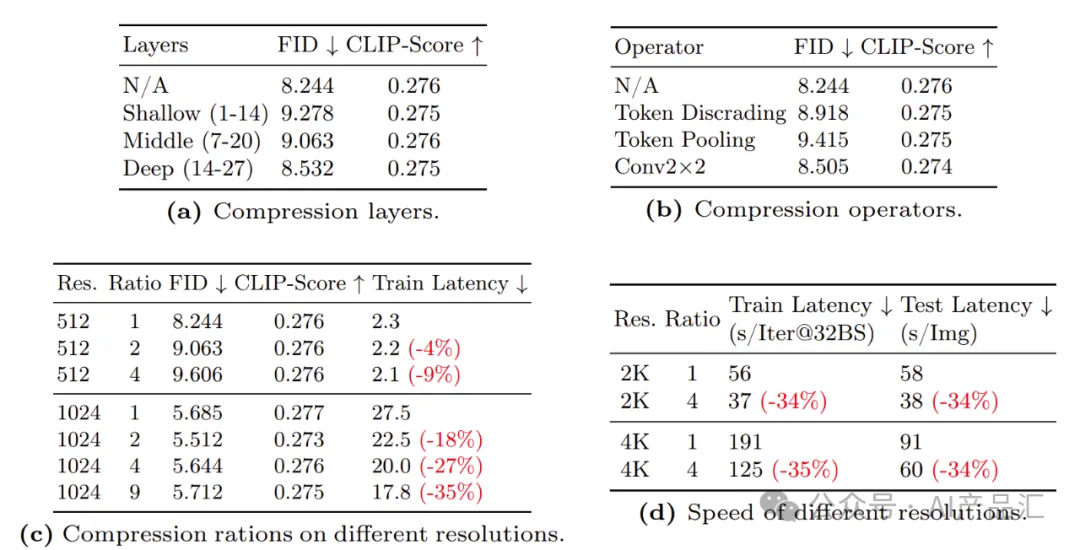
上表展示了图像生成中的KV令牌压缩设置。本研究采用FID、CMMD和CLIP Score指标来评估各种代币压缩组件的影响,如压缩比、位置、运算符和不同分辨率。
压缩位置–作者在Transformer结构内的不同深度实施了KV压缩:浅层(1~14)、中间层(7~20)和深层(14~27)。如表3a所示,在深层上采用KV压缩显著地实现了优越的性能。作者推测这是因为浅层通常对详细的纹理内容进行编码,而深层对高级语义内容进行抽象。由于压缩往往会影响图像质量,而不是语义信息,因此压缩深层可以实现最小的信息损失,使其成为加速训练但不影响生成质量的实用选择。















内容转自公众号「AI产品汇」。
相关文章


 渝公网安备50010802005100
渝公网安备50010802005100